




一、产品概述
Apache Kafka是一个开源的、分布式的、高吞吐量的流处理平台,广泛应用于大数据实时处理的场景,随着大数据时代的到来,对Kafka的性能监控和优化变得尤为重要,本文将重点介绍在历史上的12月14日这一天,如何查看Kafka的实时吞吐量,并对产品的特性、使用体验、与竞品对比、优缺点以及目标用户群体进行深入分析。
二、产品特性
1、实时性: Kafka提供了实时的数据流处理,能够确保数据在近乎实时的速度下被消费和处理。
2、高吞吐量: 支持高并发读写,能够满足大规模数据处理的业务需求。
3、灵活的主题和分区: 支持多主题和分区设置,提高了数据的灵活性和可扩展性。
4、监控工具: Kafka提供了内建的监控工具,可以查看集群的状态、主题的消费进度以及实时吞吐量等信息。
三、使用体验
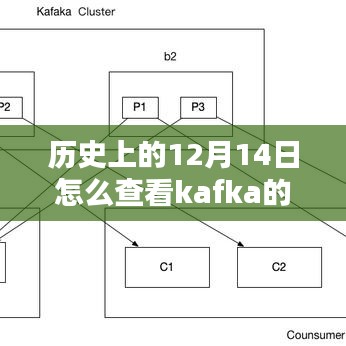
查看Kafka的实时吞吐量,通常可以通过Kafka自带的监控工具或者第三方工具来实现,在操作上,用户首先需要启动Kafka集群,并通过相应的命令或界面来访问监控数据,在界面上,用户可以直观地看到各个主题的吞吐量、延迟、ISR(In-Sync Replicas)等信息,用户还可以根据需求自定义监控指标和告警规则。
在实际使用过程中,Kafka的实时吞吐量查看体验相对良好,界面直观易懂,操作简便,即使是初次接触的用户也能快速上手,Kafka的监控数据准确度高,能够为用户提供实时的性能数据,帮助用户进行性能调优和资源分配。
四、与竞品对比
在大数据实时处理领域,Kafka的主要竞品包括Apache Flink和Spark Streaming等,与这些竞品相比,Kafka在实时吞吐量方面表现优秀,Flink和Spark Streaming也提供了实时处理的能力,但在大规模数据处理和灵活性方面略逊于Kafka,Kafka的监控工具更为成熟和全面,能够为用户提供更详细的性能数据。
五、优缺点分析
1、优点:
* 实时性好,能够满足大数据实时处理的业务需求;
* 吞吐量高,支持高并发读写;
* 灵活的主题和分区设置,提高了数据的灵活性和可扩展性;
* 内建的监控工具功能强大,能够为用户提供详细的性能数据。
2、缺点:
* 对于初次接触的用户,上手可能需要一定的时间;
* 在复杂场景下的性能调优可能需要较高的技术功底。
六、目标用户群体分析
Kafka主要适用于需要实时处理大规模数据的场景,因此其目标用户群体主要是大数据开发人员、数据工程师、流处理工程师等,这些用户通常需要处理海量数据,并对数据的实时性有较高要求,对监控和优化工具需求较高的企业用户也是Kafka的重要目标群体。
七、总结
本文重点介绍了Kafka在实时吞吐量查看方面的特性、使用体验、与竞品对比、优缺点以及目标用户群体,通过本文的介绍,读者应该对Kafka有了更深入的了解,在未来的发展中,Kafka将继续优化性能,提高易用性,为用户带来更好的体验,历史上的12月14日,是Kafka发展史上的一个重要日子,也是我们在大数据领域不断探索和进步的一个缩影。
转载请注明来自北京京通茗荟网络科技有限公司,本文标题:《历史上的12月14日Kafka实时吞吐量深度解析与查看指南》






 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...