




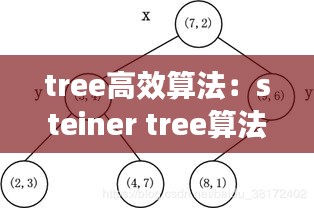
什么是Tree高效算法
Tree高效算法,顾名思义,是一类在处理树形数据结构时能够高效执行任务的算法。在计算机科学中,树是一种广泛使用的数据结构,它由节点组成,每个节点可以有一个或多个子节点。树形数据结构在许多领域都有应用,如文件系统、数据库索引、算法设计等。Tree高效算法的核心目标是通过优化算法设计,减少时间复杂度和空间复杂度,从而提高算法的执行效率。
常见Tree高效算法
以下是一些常见的Tree高效算法及其应用场景:
- 深度优先搜索(DFS):DFS是一种用于遍历或搜索树或图的算法。它从树的根节点开始,沿着一条路径一直走到叶子节点,然后再回溯到上一个节点,继续沿着另一条路径前进。DFS在查找特定节点、拓扑排序、路径搜索等方面非常有用。
- 广度优先搜索(BFS):BFS与DFS类似,也是用于遍历或搜索树或图的算法。与DFS不同,BFS是按照节点所在的层次进行遍历,即先遍历根节点所在的层,再遍历子节点所在的层,以此类推。BFS在拓扑排序、最短路径搜索等方面有广泛应用。
- 二叉搜索树(BST):BST是一种特殊的树形数据结构,其中每个节点的左子节点的值小于该节点的值,而右子节点的值大于该节点的值。BST在插入、删除和搜索操作上具有高效的性能,时间复杂度为O(log n)。
- 平衡二叉搜索树(AVL树):AVL树是一种自平衡的二叉搜索树,它通过在必要时进行旋转操作来保持树的平衡。AVL树在插入、删除和搜索操作上都具有O(log n)的时间复杂度,这使得它在需要频繁进行这些操作的场景中非常有用。
- 红黑树:红黑树是一种自平衡的二叉搜索树,它通过颜色标记和旋转操作来保持树的平衡。红黑树在插入、删除和搜索操作上都具有O(log n)的时间复杂度,常用于实现高级数据结构,如字典、跳表等。
Tree高效算法的设计原则
为了设计高效的Tree高效算法,以下是一些关键的设计原则:
- 最小化遍历路径:在设计算法时,应尽量减少遍历路径的长度,以减少时间复杂度。
- 保持数据结构的平衡:对于需要频繁进行插入、删除和搜索操作的树形数据结构,保持其平衡状态可以保证操作的效率。
- 优化递归和迭代:递归和迭代是处理树形数据结构时常用的两种方法。在设计算法时,应根据具体情况选择合适的方法,以优化性能。
- 利用缓存和记忆化:在算法中,可以预先计算并缓存一些结果,以避免重复计算,从而提高效率。
Tree高效算法的应用案例
Tree高效算法在计算机科学和实际应用中有着广泛的应用。以下是一些应用案例:

- 文件系统:在文件系统中,树形结构被用于组织文件和目录。DFS和BFS可以用于查找文件、删除文件和目录等操作。
- 数据库索引:数据库索引通常使用B树或B+树等树形数据结构来提高查询效率。这些树形结构通过平衡操作保证了高效的插入、删除和搜索操作。
- 社交网络分析:在社交网络中,用户之间的关系可以表示为一个图,而图可以转化为树形结构进行高效处理。DFS和BFS可以用于分析社交网络中的连接关系、传播信息等。
- 算法竞赛:在算法竞赛中,树形数据结构是解决某些问题的关键。例如,在解决树形DP问题时,需要使用DFS和BFS来遍历树并计算状态。
总结
Tree高效算法是一类在处理树形数据结构时能够高效执行任务的算法。通过遵循设计原则和应用常见算法,我们可以优化算法性能,提高处理树形数据的效率。随着计算机科学的发展,Tree高效算法将在更多领域发挥重要作用。
转载请注明来自北京京通茗荟网络科技有限公司,本文标题:《tree高效算法:steiner tree算法 》
百度分享代码,如果开启HTTPS请参考李洋个人博客






 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...