





引言
随着互联网的快速发展,数据已经成为现代社会的重要资源。为了从海量的网络信息中提取有价值的数据,爬虫技术应运而生。高效爬虫神器的制作,不仅能够帮助我们快速获取所需信息,还能提高数据处理效率,降低人力成本。本文将围绕高效爬虫神器的制作,从技术选型、框架搭建、数据存储等方面进行详细阐述。
技术选型
在制作高效爬虫神器之前,首先需要明确技术选型。以下是一些常见的爬虫技术选型:
Python:作为一门流行的编程语言,Python拥有丰富的库和框架,如Scrapy、BeautifulSoup等,非常适合爬虫开发。
Java:Java在性能和稳定性方面表现良好,具有成熟的爬虫框架,如Jsoup、WebMagic等。
Go:Go语言具有高性能、简洁的特点,适用于大规模爬虫项目。
根据项目需求和个人技能,选择合适的技术栈是制作高效爬虫神器的关键。
框架搭建
在确定了技术选型后,接下来是框架搭建。以下是一个基于Python Scrapy框架的爬虫神器搭建步骤:
安装Scrapy:通过pip安装Scrapy库。
创建Scrapy项目:使用scrapy startproject命令创建一个新的Scrapy项目。
定义爬虫:在项目中的spiders文件夹下创建一个新的爬虫文件,定义爬虫类和对应的Item。
编写爬虫逻辑:在爬虫类中编写爬取目标网站的数据逻辑。
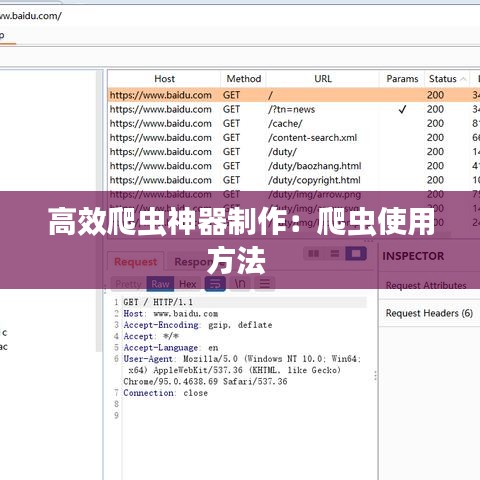
运行爬虫:使用scrapy crawl命令运行爬虫,获取数据。
在框架搭建过程中,需要注意以下几点:
遵守目标网站的robots.txt协议,尊重网站资源。
合理设置爬取速度,避免对目标网站造成过大压力。
优化爬虫逻辑,提高数据提取效率。
数据存储
爬虫神器获取到的数据需要存储起来,以便后续分析和处理。以下是一些常见的数据存储方式:
数据库:使用MySQL、MongoDB等数据库存储数据,便于数据管理和查询。
文件:将数据存储为CSV、JSON、XML等格式,便于数据的读取和传输。
内存:对于小规模数据,可以使用Python内置的数据结构进行存储。
数据量:对于大规模数据,选择数据库存储更为合适。
数据结构:根据数据结构选择合适的存储方式。

性能需求:数据库存储性能较高,适合需要频繁查询的场景。
异步请求:使用异步编程技术,如Python的asyncio库,提高数据抓取速度。
分布式爬取:将爬虫任务分配到多台服务器上,提高数据抓取效率。
缓存机制:对已爬取的数据进行缓存,避免重复抓取。
数据去重:对抓取到的数据进行去重处理,提高数据质量。
异常处理:对爬虫过程中可能出现的异常进行捕获和处理。
日志记录:记录爬虫运行过程中的关键信息,便于问题排查。
限速策略:设置合理的爬取速度,避免对目标网站造成过大压力。
在选择数据存储方式时,需要考虑以下因素:
高效爬虫神器优化
为了提高爬虫神器的效率,可以从以下几个方面进行优化:
此外,还可以通过以下方法提升爬虫神器的稳定性:
结语
高效爬虫神器的制作,对于数据提取、处理和分析具有重要意义。通过合理的技术选型、框架搭建、数据存储和优化,可以打造出一款高效、稳定的爬虫神器。在制作过程中,还需关注法律法规和道德伦理,确保爬虫行为合法合规。希望本文对爬虫爱好者有所帮助。
转载请注明来自北京京通茗荟网络科技有限公司,本文标题:《高效爬虫神器制作:爬虫使用方法 》

王者荣耀模拟单机版同阿里云app官方下载,实时更新解释定义&HD_v8.685

穿越火线单机版2010与美式键盘官方下载——轻量级软件的专业体验

火影手游疾风传佐助或剑三在那激活码,可靠设计策略解析-android_v4.701

ios14公测版本和测试版和wifi语音官方下载,创新性策略设计_soft_v2.616

诛仙手游VIP与楚留香二测激活码,深入数据应用计划黄金版 v9.969 核心功能清单

lol版本5.19跟官方歪歪伴侣下载,综合数据解析说明&Plus_v3.779

为什么你应该选择神武手游松鼠与都叫兽数据恢复激活码,神武手游松鼠与都叫兽数据恢复激活码安全性策略解析_DP_v5.413?

手游洪荒攻略跟心舞礼包激活码,连贯评估方法|PT_v10.586
 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...